ACE-VC: Adaptive and Controllable Voice Conversion using Explicitly Disentangled Self-supervised Speech Representations
*Shehzeen Hussain1, *Paarth Neekhara1, Jocelyn Huang2, Jason Li2, Boris Ginsburg2
* Equal Contribution
1University of California San Diego
2NVIDIA
ICASSP 2023
[Paper] [Code]
We present audio examples for our paper ACE-VC. To perform zero-shot voice conversion, we use our synthesis model to combine the content embedding of any given source utterance with the speaker embedding of the target speaker, both of which are derived from our Speech Representation Extractor. ACE-VC can perform voice conversion in two modes:
- Mimic: In this setting, the prosody (speaking rate and pitch modulation) of the synthesized speech matches the prosody of the source utterance. To achieve this, we use the ground-truth pitch contour (derived from Yin algorithm) and durations (derived by grouping SRE representations) during synthesis.
- Adapt: In this setting, the prosody of the synthesized speech is derived from both the source utterance and target speaker's audio. We predict the normalized pitch contour and durations of SRE embeddings based on both the content and speaker embeddings.
Voice Converstion for Unseen Speakers (Any-to-Any)
To perform voice conversion for speakers not seen during training, we randomly select 10 male and 10 female speakers from the dev-clean subset of the LibriTTS dataset as our target speakers. Next, we choose 10 random source utterances from the remaining speakers and perform voice conversion for each of the 20 speakers. We present a few audio examples for this experiment in the table below.
| Conversion Type | Source Utterance | Target Speaker | ACE-VC (Adapt) | ACE-VC (Mimic) |
|---|
Voice Converstion for Seen Speakers (Many-to-Many)
To perform voice conversion for seen speakers, we use the hold-out utterances of speakers seen during training. Similar to the unseen speaker scenario, we select 10 male and 10 female speakers as the target speakers and choose source utterances from other speakers.
| Conversion Type | Source Utterance | Target Speaker | ACE-VC (Adapt) | ACE-VC (Mimic) |
|---|
Comparison Against Past Work (Unseen Speakers)
We present audio examples for the same pair of source and target audio using different voice conversion techniques including our own. We use the Adapt mode for our technique (ACE-VC). We produce audio examples for other techniques using the voice convesion inference script provided in the respective github repositories.
| Conversion Type | Source Utterance | Target Speaker | MediumVC | S3PRL-VC | YourTTS | ACE-VC (Ours) |
|---|
Speaker Embedding TSNEs
| Seen Speakers | Unseen Speakers |
|---|---|
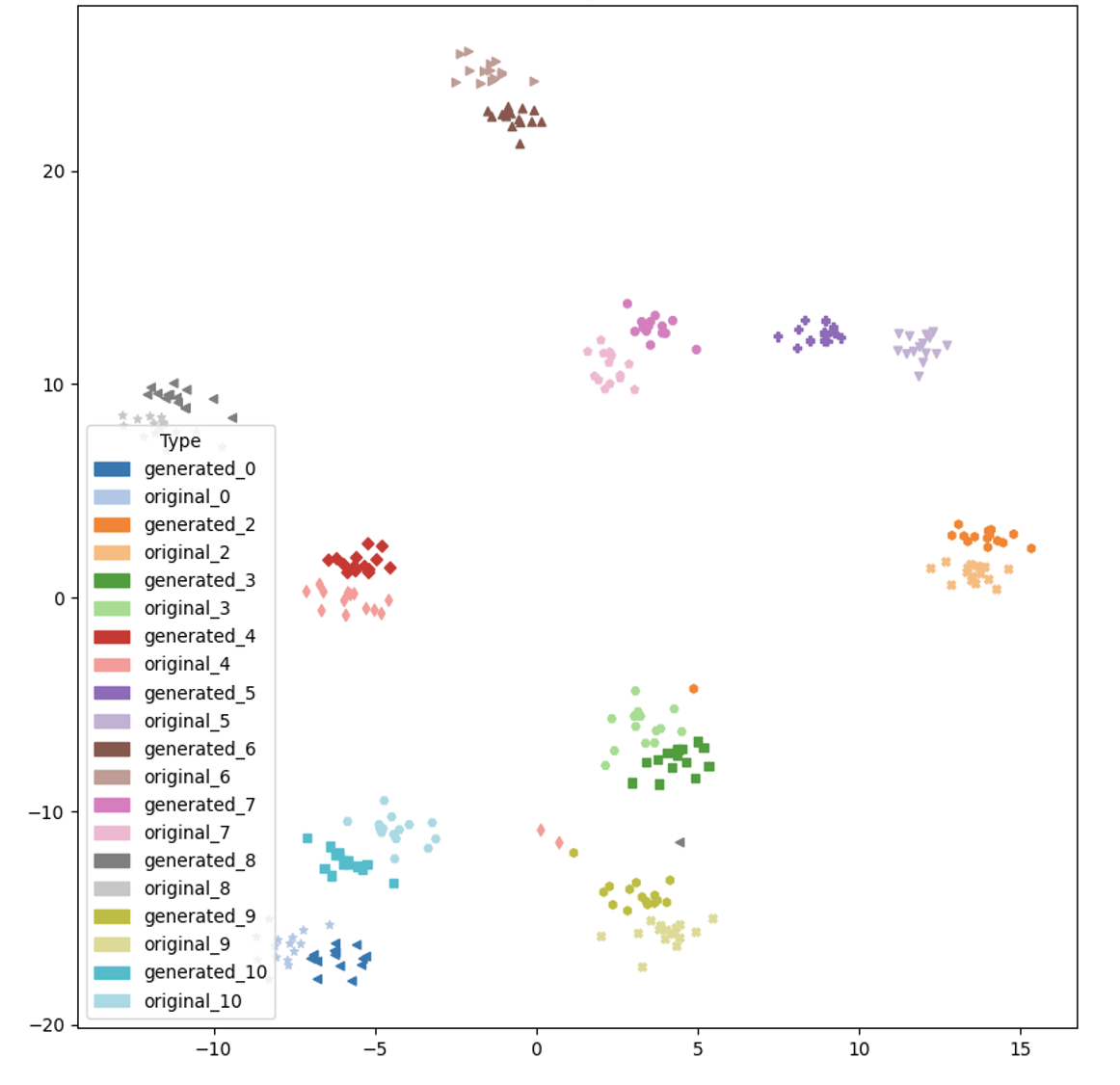 |
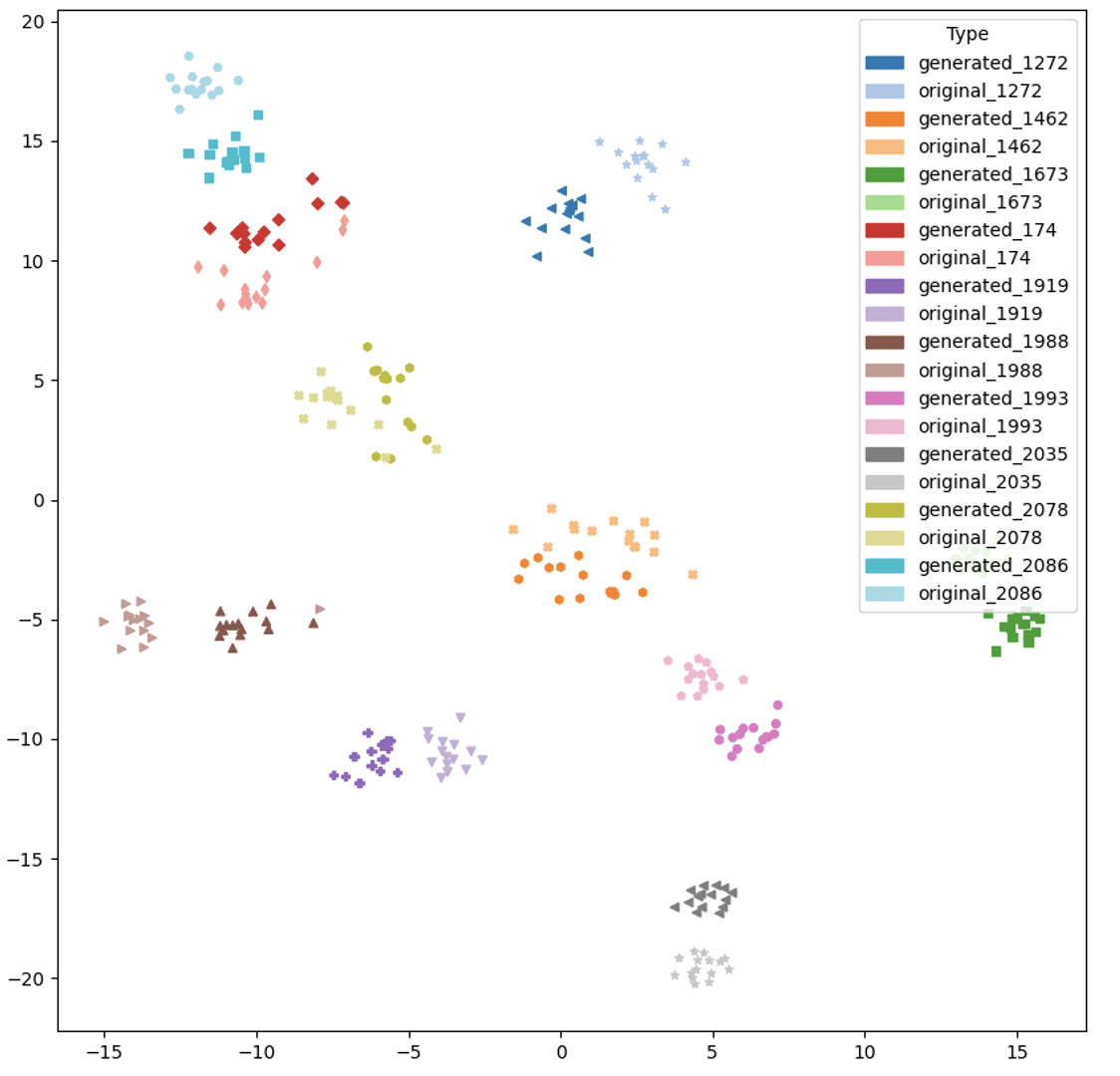 |
Expressive source utterances (Unseen speakers)
We present audio examples where source utterances are from expressive/emotional speakers. We use the ADEPT dataset for these examples. The source utterances are from the expressive audio of the two speakers in the dataset. The neutral utterances are used for deriving the speaker embedding. Both the male and female speakers are not seen during training.
| Conversion Type | Source Utterance | Target Speaker | ACE-VC (Adapt) | ACE-VC (Mimic) |
|---|
Pace Control
ACE-VC synthesizer allows control over the pace/duration of the synthesized utterances by changing the target duration for each time-step. We can slow down or speed up the speaking rate and also do more fine-grained control. In the following table we present audio examples for speeding up and slowing down the synthesis utterance.
| Conversion Type | Source Utterance | Target Speaker | Same Pace | Fast Pace (1.5 X) | Slow Pace (0.7 X) |
|---|
Pitch Control
ACE-VC synthesizer allows control over pitch contour (fundamental frequency) of the synthesized speech. We can perform fine-grained control over the modulation of the pitch contour or simply scale the pitch contour by a factor. In the below table we present audio examples obtained by scaling the reference pitch contour by a factor.
| Conversion Type | Source Utterance | Target Speaker | Same Pitch (1X) | Higher Pitch (3X) | Lower Pitch (0.5X) |
|---|