The Important Things In Life Are Often Simple
I remember these words from a lecture on Theory of Computation. The more you complicate a solution, the more specific it becomes to the problem being solved. The less you assume, the more you generalize. I’ll keep this article specific to Machine Learning and how simple things can do wonders!
Language
There is something magical about how a little child learns a language. The child is not imparted any knowledge related to the semantics or the grammar of the language. It is purely by experience and observation that the child learns the patterns in the word sequences. This way of learning becomes more exciting when we realize how well it generalizes across all languages.
There is a strong correspondence between how a Recurrent Neural Network is trained and how a child learns to speak. An RNN processes and learns from sequential information. Consider the problem of machine translation.
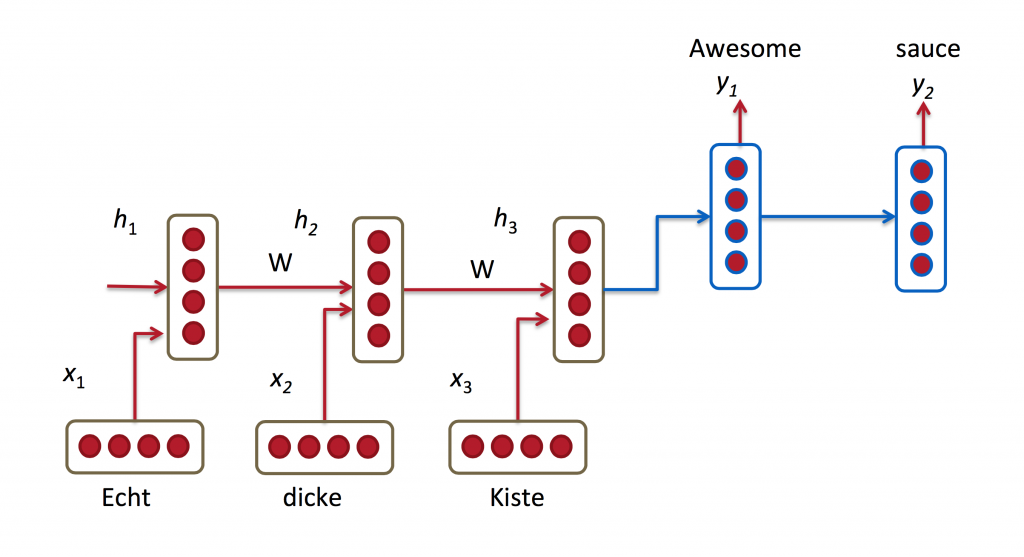
The dataset contains pairs of sentences in two languages (eg. German and English). An RNN processes the input sentence sequentially (word by word or character by character) and uses the processed information with the current word to obtain a new state. The first stage of the translation can be understood as encoding the meaning of the input sentence into a vector of numbers, popularly called a thought vector or sentence embedding. The next stage of the translation involves generating the embedded sentence in the target language, which is again done through an RNN. This simple architecture is surprisingly effective and given enough data, it can easily outperform a rule based machine translator. Without modifying anything in the above architecture, the RNN can be used for translating any pair of languages given the appropriate data set.
There are strong reasons to believe our mind interprets and generates sentences in a very similar way. The training corpus for our mind is linked across many domains. We can translate text to text (one language to another), image to text (describing an image) or even text to image (picturing a scene while reading). The cool thing is, we can simulate most of these translations on a machine as well.
Vision
Before connecting the dots between images and text, we need to encode the images in a way a unified network can work on image and text encodings. This involves capturing the image features in the form of a vector that has information about the image. Convolutional Neural Networks have produced unprecedented results in this area. I’ll not dig deep into them, but the idea essentially is to train filters on images that produce features, which are relevant to understanding its content. A CNN can work directly on top of scaled pixel values without any further preprocessing on the image. ( I am pointing this out to reiterate its simplicity).
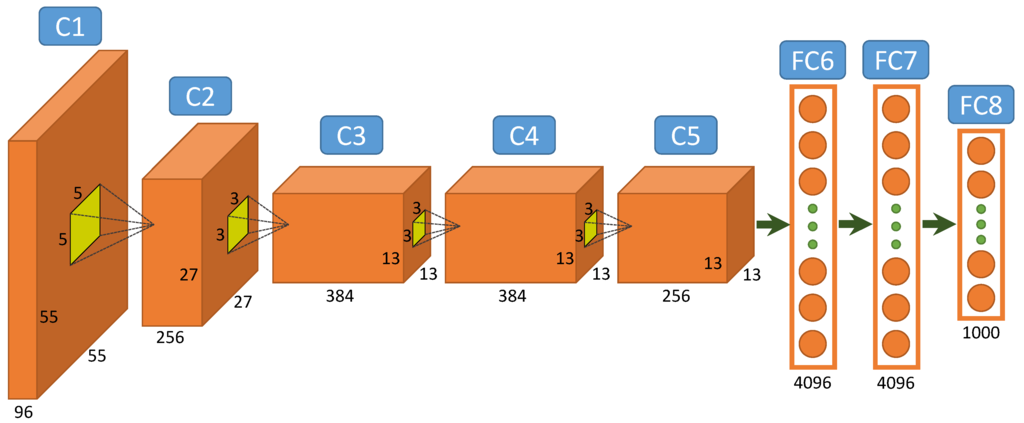
It is interesting to observe that a CNN trained for one task can be used for generating image feature vector for another. The reason is that the features of image extracted by a CNN are very generic (like edges, blobs etc) . This holds true for RNNs as well. Both CNN and RNN can be used as feature encoders for images and text respectively.
Linking It Together
The fact we are able to encode the content of both text and image in numbers allows us to link the two. We can now train our models on data linked across multiple domains - language and vision. I will elaborate on two such interesting problems - Visual Question Answering and Image Synthesis From Text.
Visual Question Answering (http://www.visualqa.org/)
 | 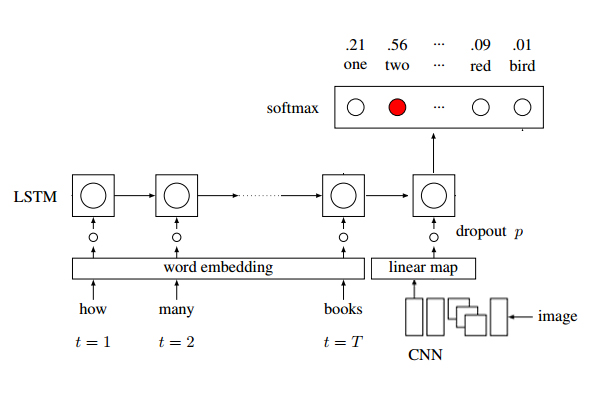 |
| Example of Visual Question Answering |
The problem definition of VQA is: given an image and a question predict an answer. The training data schema is the triplet (image, question, answer). The model architecture for this problem is shown above.
- The image is embedded using a pre-trained CNN and the 4096 dimensional image embedding vector is reduced to 512 dimensional vector (same as that of word embeddings) using a fully connected layer.
- A random word embedding (512 dimensional vector) is initialized for each word in the question vocabulary. These will be trained along with the entire model.
- The word and the image embedding are passed through an RNN (LSTM), with image appending as the last (or the first, as suggested in the paper) word for the LSTM.
- The last hidden state of the RNN is mapped to a 1000 dimensional vector(representing 1000 answers) using a fully connected layer.
Notice that this is one of the most intuitive way to connect the image and text embeddings. You can experiment with your own architectures and most of them work reasonably well. The idea is to relate the answer to text and image features, captured through RNN and CNN respectively.
Refer to the awesome torch implementation of VQA for the code. I implemented this architecture in tensorflow and it is hypnotizing to see the model training! Refer to github.com/paarthneekhara/neural-vqa-tensorflow for the code in tensorflow and sample predictions. You can play with the pre-trained model.
Image Synthesis From Text
We can picture a novel while reading it because our mind understands the correspondence between text and images. The way this is simulated on a machine, is by conditioning a generative model with the text features.
A Generative Adversarial Network is trained for generating images from random noise. An excellent blog/tutorial for understanding how they work is published by Open AI. A generative network generates an image and a discriminative network judges whether an image is a generated image or a real image. A discriminative network is trained for judging real and generated images, while the generative network is trained for fooling the discriminator by producing images that are deceivingly real.
I cannot convincingly relate this image generation with the human mind, but this concept is super interesting and effective! To link the generated images with text, a conditional generative adversarial model is used. Generative Adversarial Text to Image Synthesis - This paper implements one such conditional adversarial model.
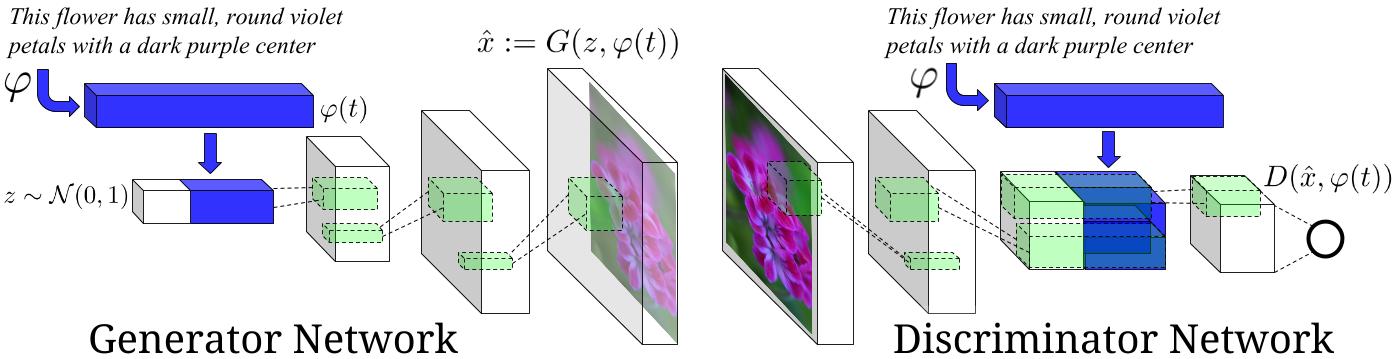
I implemented the GAN-CLS algorithm in the above paper using skip-thought-vectors for embedding the captions. Some of the sample predictions are:
| Caption | Generated Images |
|---|---|
| the flower shown has yellow anther red pistil and bright red petals |  |
| this flower has petals that are yellow, white and purple and has dark lines |  |
| the petals on this flower are white with a yellow center |  |
| this flower has a lot of small round pink petals. |  |
| this flower is orange in color, and has petals that are ruffled and rounded. |  |
| the flower has yellow petals and the center of it is brown |  |
Refer to github.com/paarthneekhara/text-to-image for the code and a pre-trained model.
It did not seem all that simple :/
cs231n.github.io and the lectures <3 . That’s all you need :D .